Hands-On 2: Allow more Analytics jobs to run
In this hands-on, we will first import a Data mining model, then run an analytics pipeline and observe what happens behind the scene. Then we will look at the configuration to see how we could improve the performance. (Tip #6)
Step-by-step instructions
Import the Data Mining model
-
If not already open, open the SAS App (there is an icon on the Desktop:
 )
)-
Login as student/Metadata0.
-
Choose Yes when asked to opt in to all of your assumable groups.
-
Click the little hamburger icon at the top on the left hand side
 .
.
-
-
In the SAS App, select Build Models.
-
Click the 3 little dots on the right hand side, then select Import then Data Mining and Machine Learning.
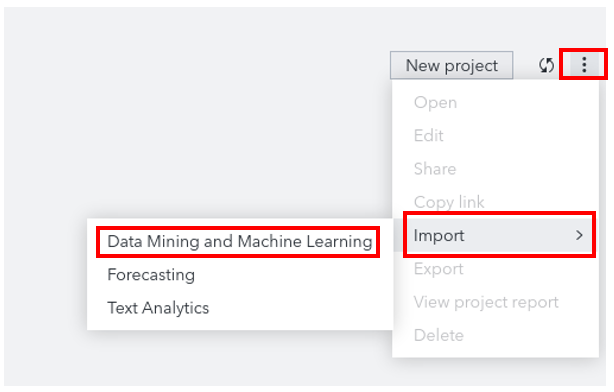
-
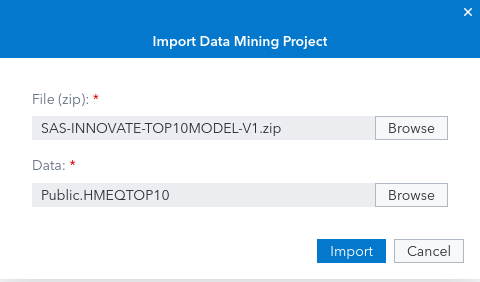
It will open a new dialog window Import Data Mining Project.

-
Click the Browse button for the File(zip), navigate to /workshop/top10tuning.
-
Select the file named SAS-INNOVATE-TOP10MODEL-V1.zip and click Open.

-
Back to the Import Data Mining Project window, click the Browse button, this time for Data.
-
Click the Import tab, select Local files, then chose Local file.
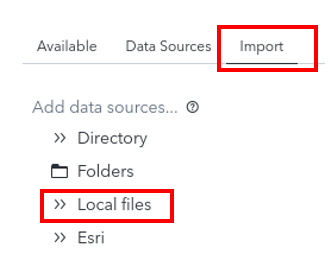
-
Select the file named hmeqtop10.csv in the /workshop/top10tuning folder and click Open.

-
Don’t change anything and click the Import item blue button.
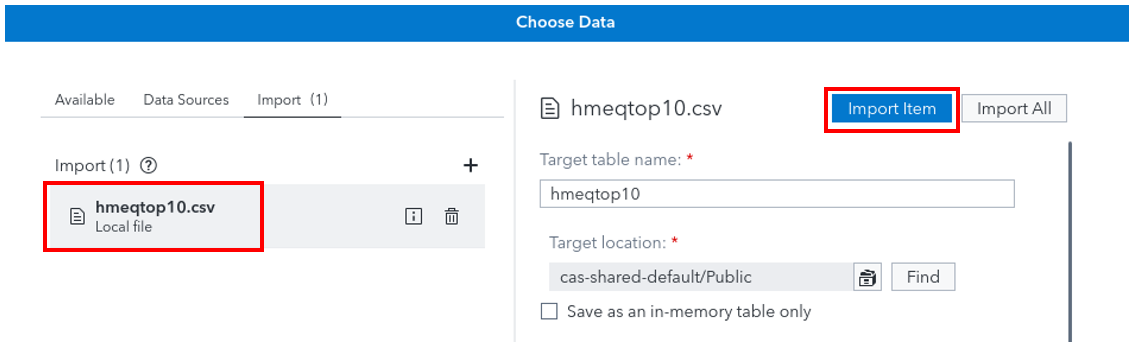
-
You will see a message like:
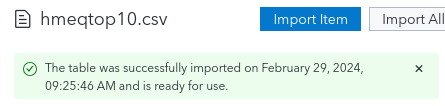
-
Click OK.
-
Click Import in the Import Data Mining Project dialog.
-
You will see a first notification that the project import has started.
-
Wait a little bit until you see another notification that the model was imported with success !

Run the pipeline and monitor the SAS Compute servers
-
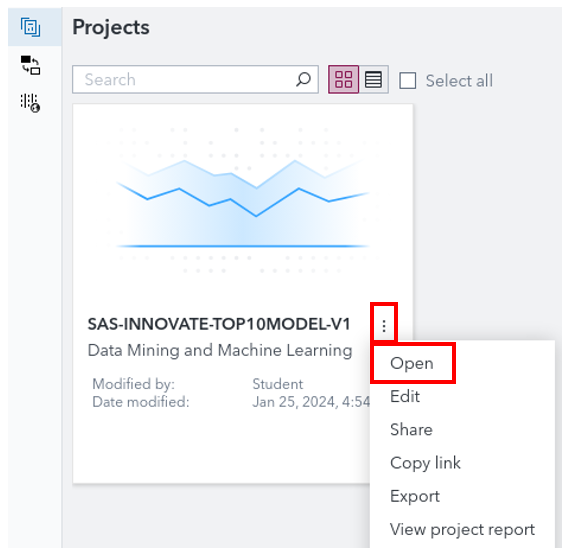
Select the SAS-INNOVATE-TOP10MODEL-V1 project, click the 3 little dots near the project name, and select Open.
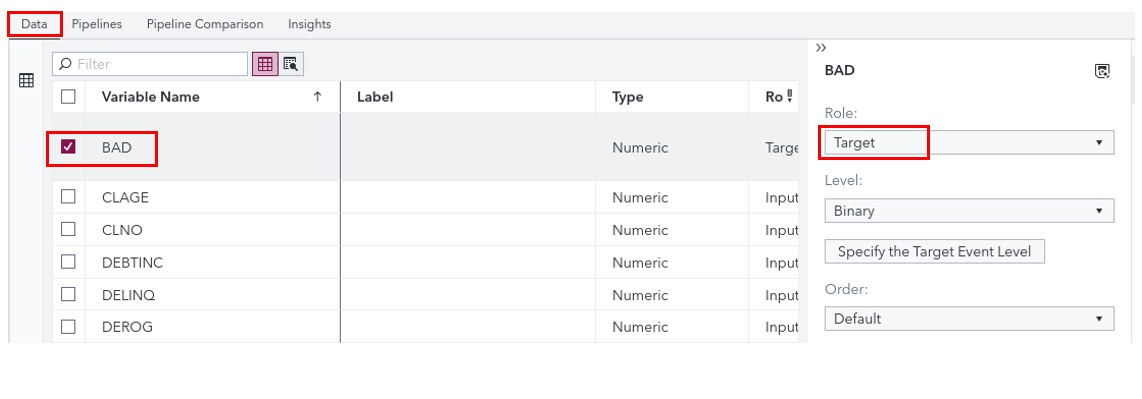
-
The project is opened on the Data tab, select the first column (BAD) and make sure that its Role is set to Target.
-
Now, in Model Studio, click the Pipelines tab, you should see something like this:
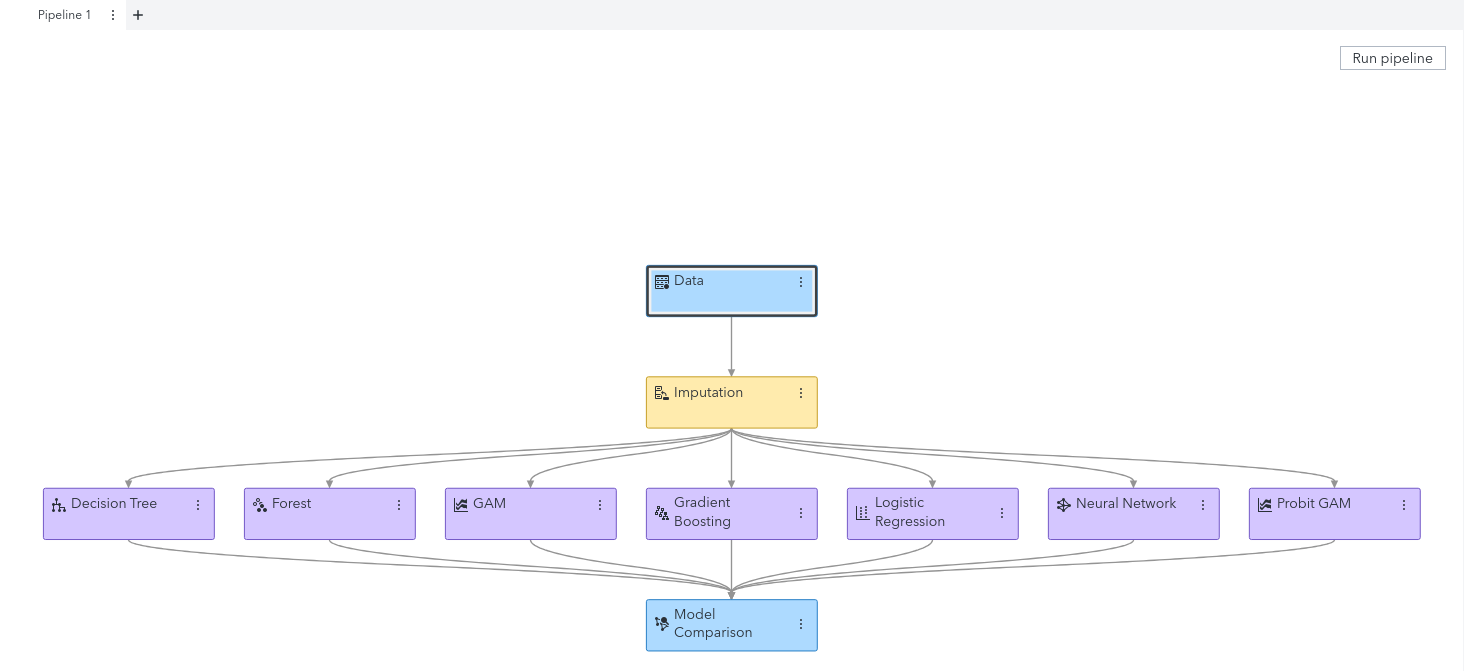
-
Before running the pipeline, we want to monitor the Compute sessions that will be started for the pipeline execution.
-
Open the Root Terminal window from the icon on the desktop.
-
Type the following command:
watch 'kubectl -n edu get pod -l launcher.sas.com/username=student' -
then resize the windows so you can run the pipeline and see the Terminal window.

-
Now, click Run pipeline.
-
You will see new pods corresponding to new SAS Compute sessions, being initialized then started.

- Notice that first there is only one Compute session (to run the data imputation node) at the begining,
- Then, when all the analytics nodes could run in parallel, no more than 3 Compute servers are running.
- After a few minutes, you should see a popup message “The pipeline has completed”.
- In your Root Terminal window, type
<Ctrl+C>to interrupt the “watch” command. - Leave your Root Terminal window open.
Check the number of Maximum concurrent nodes
Let’s see why no more than 3 compute sessions are started in parallel.
-
Now, in the SAS App, click the little hamburger icon at the top on the left hand side
. -
Select Manage Environment.
-
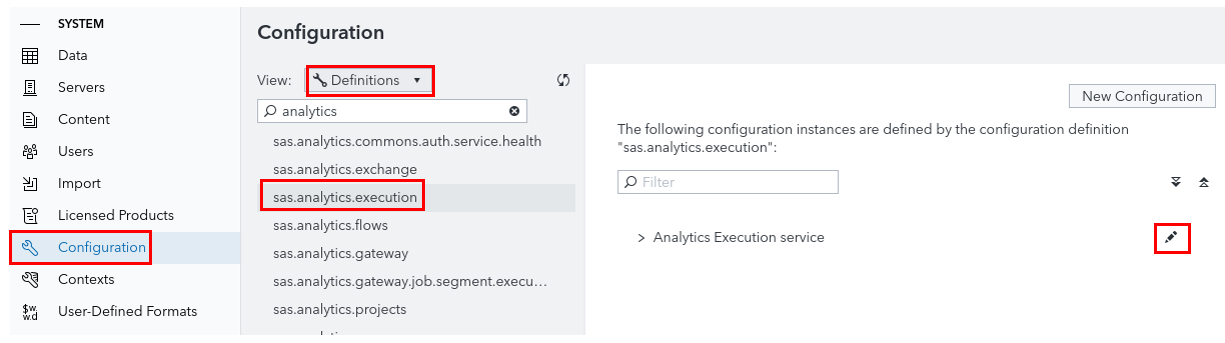
Click the Configuration icon
 on the left hand side.
on the left hand side. -
Select Definitions (in the top “pull-down” menu).
-
Select sas.analytics.execution (list item).
-
Click the edit button
 .
.
-
Scroll down until you find the Maximum Concurrent Nodes settings.

- That explains why we only saw up to 3 compute servers running at the same time.
- We could change the value, then duplicate and test our pipeline again and we would see that more analytics node can run in parallel and more Compute Servers pods would be started.
-
But there are other hands-on to do ! so let’s move to the next Hands-on
Note: If, however you want to see the effect of the change, you can watch the recordings of this hands-on which have been made available for you.
Optional : change the value of Maximum Concurrent nodes
--- Expand this ONLY if you want to change the values of the Maximum Concurrent nodes ---
- We will use the
sas-viya CLIto change the Viya configuration. -
Copy and paste the following commands, in the Root Terminal window, to login with the SAS Viya CLI.
sas-viya --profile Default profile set-endpoint "https://server.demo.sas.com/" sas-viya auth login -u Student -p Metadata0 -
Copy and paste the following commands to get the identifier for
sas.analytics.executiondefinition:ITEM="sas.analytics.execution" MEDIATYPE=$(sas-viya configuration configurations download -d $ITEM | jq -r '.items[]["metadata"]["mediaType"] ') -
Create a JSON file (specifies a change from
3to10concurrent nodes):tee ./update-$ITEM.json > /dev/null << EOF { "items": [ { "metadata": { "isDefault": false, "mediaType": "${MEDIATYPE}", "services": [ "analyticsExecution" ] }, "maximum.concurrent.node.execution": 10 } ] } EOF -
Apply the change:
sas-viya configuration configurations update --file ./update-$ITEM.json - Validate the change:
- Using the sas-viya CLI:
sas-viya configuration configurations download | grep maximum.concurrent.node.execution- And note the new value:
"maximum.concurrent.node.execution": 10, - Finally, if you want to test the effect of the configuration change in Model Studio, you need to duplicate the pipeline before running it again withe the changed value for Maximum Concurrent nodes.
What have we learned ?
What we have seen here, is that the maximum number of pipeline nodes that can be running in parallel is driven though a specific settings maximum.concurrent.node.execution. If the value is too low it will prevent multiple independant analytics nodes to run in parralel.
If the cluster capacity allows it, the performance of the Analytics pipeline could be improved by increasing this value.
References
- Documentation:
- Machine Learning Advanced Topics - Configuration Properties
- SAS® Viya® Platform Administration documentation > Configuring your environment > How to (CLI).
- Blog:
- hands on / HO1 Enable Progressive App
- hands on / HO2 Allow more analytics jobs to run<-- you are here
- hands on / HO3 Create a pool of reusable compute servers
- hands on / HO4 Increase Compute pod CPU limit
- hands on / HO5 Tune temporary storage locations CAS DISK CACHE
- hands on / HO6 Tune temporary storage locations SASWORK